
Designing
AI Quality Systems
Part 1:
Floor / Ceiling / Style for
AI-Generated Commerce Video
December 9, 2025 · Kenneth Hung · 20 min read
I've spent 15+ years productizing emerging technology, including 6.5 years at Meta where I shipped industry-first AI/ML experiences in AR and Avatars that reached 1.3B+ users across Messenger, Instagram, and Facebook. The work was always the same shape: take a novel technical capability, productize it through experiences and tools, then grow the ecosystem that scales it.
This case study applies that practice to generative AI, using TikTok Shop as the test case. Earlier capabilities didn't force the question generative AI does:
How do you specify acceptable behavior for multi-modal AI-generated content at scale? And how do you build the systems creators, ML pipelines, and global markets can all rely on and trust?
The substance of this piece isn't TikTok Shop. It's a framework called Floor / Ceiling / Style for translating human judgment into machine-learnable signals.
1. The Problem:
Why Generative AI Needs a Quality Discipline
AI Quality problem
Generative AI has solved a generation problem. It hasn't solved a quality problem.
In social media e-commerce video, that quality problem is a trust problem. Plausible video, text, and images can now be generated at near-zero marginal cost. What hasn't kept pace is trust. Users sense AI when they see it. They scroll past, distrust, or actively reject it. And when buyers don't trust the video, they don't buy.
The model is the easy part. Specifying behavior is the hard part.
Without a quality infrastructure underneath the generation, three things happen at scale:
Safety failures (Floor). Some output is technically broken or policy-violating. At scale, even a 0.1% failure rate becomes daily PR and legal exposure.
Quality drift (Ceiling). Without a benchmark for excellence, average quality regresses toward the mean of training data that's increasingly AI-generated itself. The feedback loop degrades.
Context mismatch (Style). Generic output doesn't serve specific contexts. An excellent beauty video and an excellent enterprise demo share almost no surface features.
This is what responsible AI looks like in practice: not a separate ethics review at the end, but a quality system woven into how content gets generated, evaluated, and shipped.
Four reasons TikTok Shop is the right test case for this framework.
-
Shoppable video is the category, not just TikTok Shop
TikTok Shop is the sharpest version of the AI quality problem available right now, but it's not the only one.
TikTok Shop has proven the shoppable-video commerce model at Western scale, and the entire industry is now chasing it.
Amazon launched its AI Video Generator for sellers in June 2025, making AI-generated product videos free for any Amazon merchant. Instagram Shop and YouTube Shop follow the same shoppable-video playbook.
Social commerce as a category is projected to grow from $2.6T globally in 2026 to $8.5T by 2030.
Generative AI is how every one of these platforms plans to fill the content gap.
-
TikTok Shop is the leading edge by the numbers
In 2025, TikTok Shop hit $64.3B in global GMV (+94% year-over-year)
Built a $15.1B US market across 803,500 active stores and 15.4M creators, and grew to $13.1B in Indonesia, its second-largest market globally.
As of early 2024, TikTok Shop held 68.1% of US social shopping GMV (more than Instagram Checkout and Facebook Shop combined).
-
TikTok Shop has inverted the e-commerce funnel
The structural significance is bigger than the numbers.
Products no longer wait to be searched for. They find consumers through content the consumers were already watching.
That model only works if the content is good across categories, markets, and regulatory regimes.
-
Multi-modal AI is the only realistic path
Generative AI is the only realistic path to producing that volume of category-specific, market-adapted commerce video.
Commerce video is multi-modal by nature: visual, audio, text, and temporal pacing all working together.
That makes TikTok Shop the largest live test of whether multi-modal AI-generated content can hold up at consumer scale, and what works here will define how Amazon, Meta, and YouTube approach the same problem next.
The Universal Challenge
The challenge isn't generating commerce video. That's solved across every major platform.
The challenge is generating commerce video that converts, in markets where attention costs money and ecosystem trust is the long-term asset. Without a quality framework, AI-generated commerce content at scale becomes "AI slop" on any platform that ships it. High views, low conversion, ecosystem damage.
This piece is about the infrastructure that prevents that. Built once, applicable everywhere.
2. The Framework:
Floor / Ceiling / Style
The function that codifies AI behavior goes by different names across the industry: Model Behavior, Model Policy, Responsible AI, Trust & Safety, Content Integrity. The naming differs. The work is converging. I've written separately about AI Behavior Design as a discipline.
For TikTok Shop specifically, the mission is narrower:
Build AIGC for commerce conversion, not entertainment virality.
Learn from high-GMV videos, not high-view videos.
Those rarely overlap, and the difference between them is what the framework has to encode.
Three-Layer Quality Framework
Why three layers, not one
Most quality systems start as a single pass/fail threshold. This works briefly, then breaks. Single thresholds can't distinguish "policy violation" from "underperforming output" from "off-brand for this category." Each requires a different intervention.
Three layers separate three distinct questions:
Floor: Is this output safe to ship? (binary, hard constraint)
Ceiling: Does this output match our top-performing examples? (numeric, optimization target)
Style: Does this output match its context? (categorical, conditioning signal)
-
The Floor catches catastrophic failures. Technical defects, policy violations, structural breakage. Floor is binary by design. There is no "70% compliant." Either output ships or it doesn't.
Implementation is classifier gating, post-generation processing, and rule-based filters. For TikTok Shop, Floor signals span every modality of the video:
Visual. Resolution, stability, brightness
Audio. Clarity, signal-to-noise ratio
Text. Banned-word and regulated-claim detection, OCR for product info accuracy
Temporal. Caption readability, absence of early-exit patterns
If output fails Floor on any modality, downstream evaluation doesn't run. It doesn't matter how high it would have scored elsewhere.
-
The Ceiling is what excellent output looks like, derived from actual top-performing content in each category. This is where the system learns excellence, not just compliance.
Implementation is numeric scoring (0-100), via reward models trained on top-decile examples.
For TikTok Shop, Ceiling signals come from high-GMV examples (not high-view), and include:
3-second hook retention ≥ 80%
First product appearance ≤ 5 seconds
Completion rate above category average
CTR/CVR above category average
Pain → solution narrative structure
Optimized CTA placement and timing
Ceiling signals must come from data, not assumptions.
The work is forensic: extract top performers, contrast against the bottom, identify differentiating patterns, validate via A/B testing. The output is a numeric quality score that ML pipelines can optimize against.
-
Style isn't about quality. It's about match. A quietly elegant beauty tutorial and a high-energy fast-cut sneaker drop can both be excellent, and both fail if you swap their styles.
Implementation is categorical labels via style embeddings or conditional generation. For TikTok Shop, Style breaks into two axes:
Format (how content is structured): Unboxing, Tutorial, Before/After, ASMR, Narrative, Fast-cut, Lifestyle, Skit, Vox Pop.
Aesthetic (how it looks): Clean Girl, Dopamine, Y2K, Quiet Luxury, Cyberpunk, Japandi, Cottagecore, Old Money, Industrial.
The product of Format × Aesthetic × Category produces an "optimal style" recommendation. Style is highly localized, with the lowest reuse rate across markets and the highest refresh rate over time.
-
Every generated piece passes through the pipeline in order:
Floor check. Pass or reject.
Ceiling score. 0-100, optimization signal.
Style match. Categorical fit to context.
Floor is what the system must do. Ceiling is what the system aims for. Style is how the system adapts. The layered structure is what makes the framework scale.
high-CVR videos
low-CVR videos
that differ
correlations
signals
3. Annotation in Practice:
Turning Judgment into Training Signal
The framework defines what to measure. Annotation is how that measurement becomes data the system can learn from.
This is the most leveraged part of the system, and the part most often underbuilt.
Turning judgment into training signal
Each video gets labeled across three layers, each with a different data type and annotation method. Floor uses auto-detection. Ceiling derives from real performance. Style is human classification.
The non-negotiable baseline. Most signals are detectable automatically using CV, ASR, NLP, and OCR. Human annotation enters only at boundary cases.
visual: 1, audio: 1,
compliance: 1, product_info: 1,
captions: 1, early_exit: 1,
pass: true
}
Derived from actual top-performing content per category. Labels come from real platform data, not human judgment. Reward models learn what high-GMV content does differently.
hook_3s: 0.92, completion: 0.68,
cvr: 0.042, structure: 0.87,
product_seconds: 2, cta_position: 0.85,
score: 94
}
Style is conditional, not absolute. A Y2K aesthetic isn't better than Quiet Luxury — it's better for a category. The framework tags style instead of scoring it.
format: "tutorial",
aesthetic: "clean girl",
category: "beauty"
}
Three layers, three annotation methods
Each layer needs a different annotation method. Floor uses multi-modal detection. Ceiling joins data. Style requires human judgment.
-
Computer vision for visual quality, ASR for audio, NLP for compliance, OCR for product info. Human annotation enters only at boundary cases.
-
Labels come from real platform data. Actual retention. Actual CVR. The work is building the pipeline that joins generated content to its performance metrics.
-
Annotators don't decide if a video is good. They classify it as Tutorial-format, Clean-aesthetic, Beauty-category. Inter-rater agreement (Cohen's kappa) above 0.7 is the quality bar.
Three learning signals from one schema
Top performers teach the model what to reproduce. Floor failures teach what to refuse. Low performers teach where the gap is between average and excellent.
30s Beauty Lipstick Tutorial
45s Fashion Showcase
60s Electronics Unboxing
From raw video to a single annotated record
Five stages turn raw video into the records shown above. Reproducible at scale, auditable per stage. Output: one combined record per video.
Bottom 10%
via classifiers
platform data
Category
Kappa > 0.7
"video_id": "sv_12345",
"floor": {
"visual": 1, "audio": 1, "compliance": 1,
"product_info": 1, "captions": 1, "early_exit": 1,
"pass": true
},
"ceiling": {
"hook_3s": 0.92, "completion": 0.68,
"cvr": 0.042, "product_appearance_seconds": 2,
"score": 94
},
"style": {
"format": "tutorial", "aesthetic": "clean", "category": "beauty"
}
}
Why this transfers beyond TikTok Shop
The same annotation discipline applies to any generative AI product, single-modal or multi-modal:
For an LLM assistant: Floor is policy compliance. Ceiling is helpfulness on top-rated responses. Style is tone match.
For multi-modal models: The same three layers apply per modality and across modalities.
The framework transfers because the underlying problem (translating judgment into signal) transfers.
4. Trust, Bias,
& Responsible AI
The framework above defines what good looks like and how to measure it. Now the harder question:
What happens when the system gets it wrong, or gets it right for the wrong people?
Quality systems are usually framed as a conversion problem. That's the surface answer. The deeper reason quality systems matter is trust — and trust gets broken in two distinct ways:
Externally, when AI-generated content erodes consumer confidence in the platform.
Internally, when the system produces high-quality output for one demographic and lower-quality output for everyone else, without anyone noticing.
Both failure modes share a root cause: codifying behavior without specifying who that behavior serves.
This section covers both.

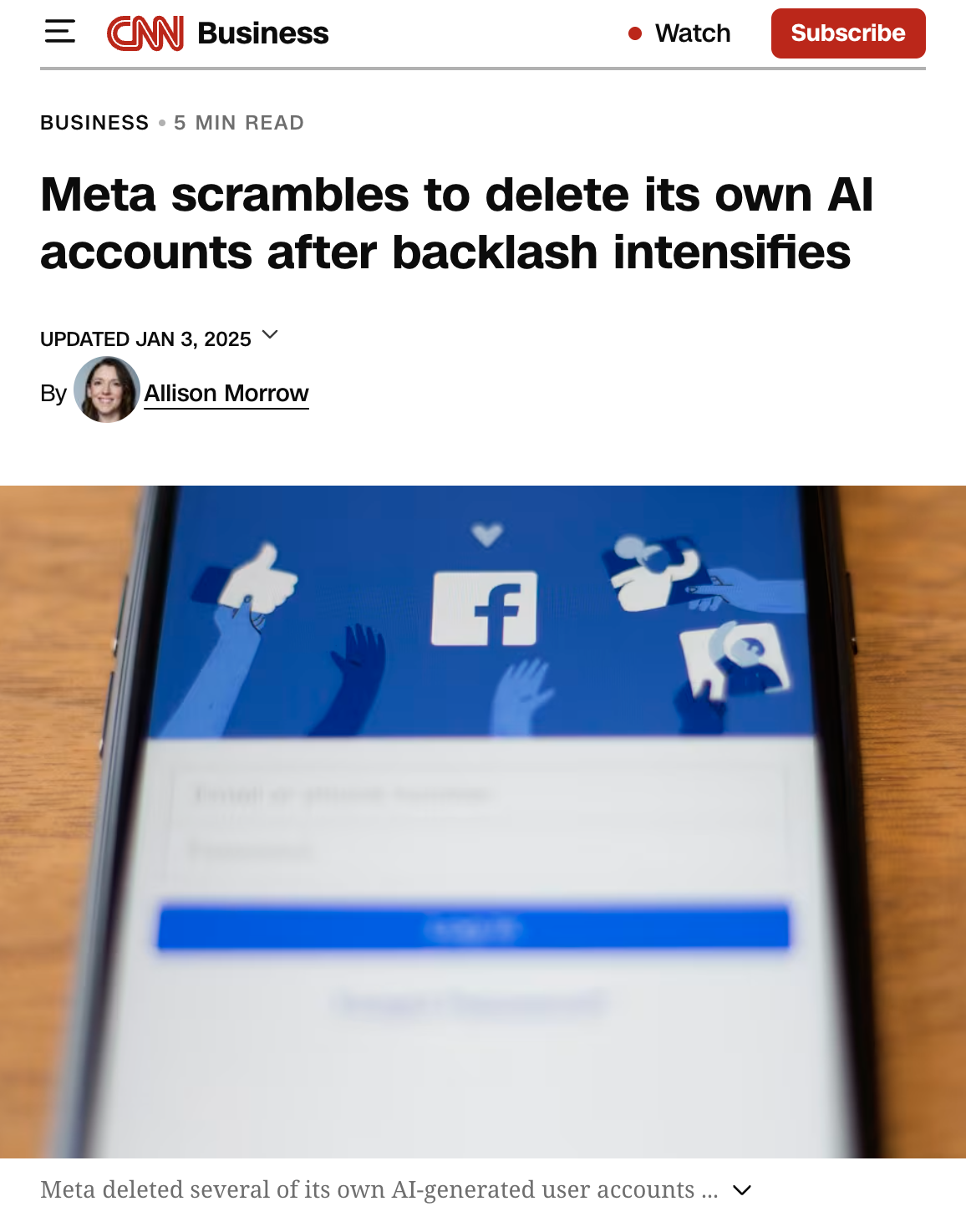
The trust contrast happening right now
Instagram. Meta has been pushing AI-generated content into feeds aggressively. AI characters with profiles. AI-generated comments. AI imagery in recommendations. The user backlash is visible and loud. The "dead internet" discourse moved from niche to mainstream. The technical capability is there. The trust isn't.
TikTok. The brand is built on the opposite. Authenticity. "Real People, Real Reviews." Creators talking to camera. The platform's value proposition collapses if AI-generated content erodes that perception.
The cost of getting it wrong:
A 0.1% Floor failure rate is a daily lawsuit.
A 5% drop in perceived authenticity is an existential threat.
Quality is the surface goal.
Trust is what's actually at stake.
The Three-Layer Quality framework treats trust as something the system actively protects, not something it hopes to maintain. Three places trust shows up in the framework:
Floor as a trust boundary.
Floor is binary because trust is binary.
One viral AI video making medical claims it can't back up doesn't lose a sale. It loses platform credibility for a category.
These are the guardrails the system can't cross.
Ceiling as a trust signal.
Completion rate and CVR aren't just performance metrics. They're trust proxies.
People stay because they trust the content.
People buy because they trust the seller.
Style as a trust match.
Generic AI output is recognizable.
Distinctive AI output that matches its category and audience doesn't feel out of place.
Style prevents the uncanny-valley sensation of "this content doesn't belong here."
A structural parallel
Different labs encode AI behavior using structurally similar mechanisms. Anthropic's Constitutional AI. OpenAI's Model Spec and RLHF. Google DeepMind's safety rules and preference learning. Each one names the same architecture: hard constraints, learned preferences, human judgment translated into machine-learnable signals.
The domains differ. The structural shape is the same: specifying acceptable AI behavior in a way the system can learn and the audience can trust.
Where the system quietly breaks: bias
If the previous part of this section was about why trust matters externally, this part is about how trust gets quietly broken internally.
Responsible AI isn't a separate discipline from quality. It's the part of quality that asks: who is this system working for, and who is it leaving out?
A quality framework that doesn't account for bias produces high-quality biased output. Bias isn't binary. It's not "have it or don't." It's "more or less." The goal isn't claiming neutrality, which is unachievable. The goal is building mechanisms that continuously detect and reduce bias as the system runs.
Codifying behavior without asking "behavior for whom" is how that happens.
A quality framework without this layer ships biased output more efficiently. With it, the framework becomes responsible AI infrastructure.
-
Training data bias. The Top 10% of high-converting content reflects what the platform has historically rewarded. If past high performers were mostly young, light-skinned, conventionally attractive models, Ceiling signals encode that pattern. The system doesn't learn what makes a video convert. It learns what convertible videos have looked like so far.
Prompt-implicit assumptions. "A beauty influencer" defaults to young and female. "A professional look" implies a specific skin tone, age, and dress. These assumptions aren't explicit, but they shape generation.
Style label bias. Style categories themselves can encode bias. Does "high-end" map to one specific aesthetic? Does "professional" implicitly exclude certain body types?
-
Data layer. Audit demographic distribution per category. Supplement deliberately where coverage is thin.
Prompt layer. Review templates for implicit assumptions. "A skincare user" instead of "a young woman with clear skin."
Detection layer. Build classifiers that flag patterns at the distribution level, not just individual outputs.
Output layer. Audit regularly. Distribution analysis, not random spot checks.
Feedback layer. User reporting. Internal red teams. Find problems before users do.
-
A diverse quality team. Different perspectives find different blind spots.
External audits. Internal teams develop collective blind spots.
Bias bounty mechanisms. Crowdsourced detection beats centralized review.
Continue to Part 2
The framework above is general. Most quality systems break the moment they meet specifics: different verticals demand different signals, different markets demand different rules.
Part 2 covers how the framework scales — eight verticals with their own Floor / Ceiling / Style configurations, three markets launching the same product under different regulatory regimes, and the 90-day execution plan for building this from zero.